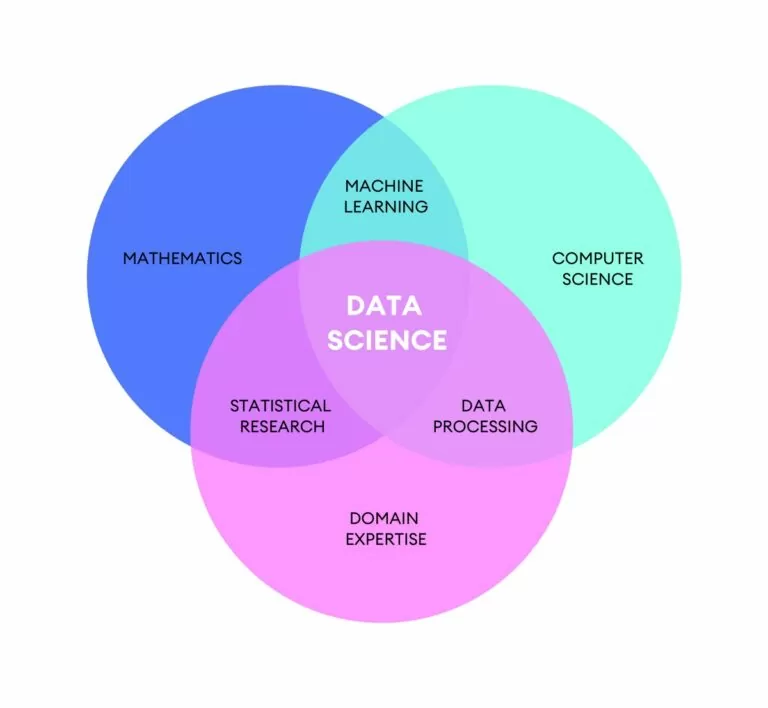
La Data Science, ose Data Science, është një shkencë relativisht e re, në fakt ajo ka rreth pesëdhjetë vjet. Ajo lind nga nevoja për të vendosur rregull në një kontekst shumë të gjallë dhe me zhvillim të shpejtë. Rritja e vëllimit të të dhënave, mundësia dhe aftësia për t'i dhënë kuptim të dhënave, kanë bërë që të Data Science.
Historikisht, të dhënat shpesh janë trajtuar si një lloj produkti dytësor i çdo procesi. Kushdo gjatë shekujve ka marrë përsipër të mbledhë të dhëna, e ka bërë këtë kryesisht për lehtësinë e tij, shpesh pa e imagjinuar se sot një vlerë ekonomike mund t'i atribuohet një koleksioni të dhënash. Nëse mendojmë, për shembull, për një fermë që me kalimin e viteve mund të ketë mbledhur informacion mbi të korrat, ngjarjet, mbjelljet, etj., ndoshta mund ta kishte bërë këtë për të arkivuar historinë e saj të korporatës. Nëse të gjitha fermat do ta kishin bërë atë metodë, atëherë kompanitë e plehrave sot mund të përfitonin prej saj për qëllime kërkimore, ose për qëllime marketingu.
Ai që merret me Data Science, quhet ai shkencëtar i të dhënave: aktualisht një nga profesionistët më të kërkuar në botën e punës.
Detyra e shkencëtarit të të dhënave është të analizojë të dhënat në mënyrë që të identifikojë modelet brenda tyre, domethënë atë që unë shpreh të dhënat e disponueshme përmes trendit. Identifikimi i këtyre modeleve është funksional për qëllimet e klientit: kompani, organ publik etj.
Vitet e fundit, një model i marketingut të të dhënave është vendosur gjithnjë e më shumë ku dikush është i interesuar të shesë të dhëna dhe dikush tjetër t'i blejë ato.
U lindën kompani të specializuara në prodhimin e të dhënave dhe kompani të specializuara në blerjen dhe shitjen pas operacioneve të duhura të pastrimit dhe ripërpunimit. Nëse më pas mendojmë për rregulloret e privatësisë, kuptojmë kompleksitetin e temës. Sot ka ligje strikte që kërkojnë një përdorim të ndërgjegjshëm dhe të respektueshëm të informacionit.
Një projekt nga Data Science zakonisht përbëhet nga hapat e mëposhtëm:
Në çdo hap të vetëm shkencëtar i të dhënave ndërvepron me departamente të veçanta të kompanisë, dhe për këtë arsye mund të themi se shkencëtar i të dhënave është e integruar në mënyrë të përkryer në realitetin e korporatës.
Me përparimin teknologjik, shkencëtar i të dhënave ai shpesh është përballur me problemet e të dhënave të mëdha dhe inteligjencës artificiale.
Kur flasim për Big Data i referohemi të dhënave që përmbajnë një larmi të madhe, duke arritur në vëllime në rritje dhe me shpejtësi më të madhe. Ky koncept njihet edhe si rregulli i tre V-ve, i cili konsiston në zgjedhjen e tre termave që karakterizojnë fenomenin Big Data në tiparet e tij thelbësore:
Në realitet, me kalimin e kohës janë shtuar edhe veçori të tjera, siç është vërtetësia e të dhënave për të identifikuar besueshmërinë dhe besueshmërinë e të dhënave.
Vëllimi i madh i të dhënave që mbërrijnë me shpejtësi të madhe dhe karakterizohen nga shumëllojshmëria e madhe, domosdoshmërisht çojnë në probleme të organizimit të të dhënave.
I mirëpresim dhe më pas i përpunojmë? Strukturimi i tyre dhe më pas përpunimi i tyre?
Kanë lindur disa paradigma të organizimit të sistemeve të të dhënave, të cilat janë krijuar me kalimin e kohës:
Aktualisht këto janë paradigmat më të përdorura dhe në shumë raste mbizotëron zgjidhja e integrimit, dmth. projekte të ndryshme mund të përdorin metodologji të ndryshme akumulimi dhe më pas të integrohen më vonë. Mund të ketë situata në të cilat të dhëna të ndryshme mblidhen me paradigma të ndryshme, ose koleksione të ndryshme mund të përbëjnë faza të njëpasnjëshme të të njëjtit cikël jetësor.
Pavarësisht dobisë së tyre të madhe, ne e dimë shumë mirë se makinat përpunuese ose kompjuterët janë budallenj. Kjo do të thotë, një kompjuter nuk mund të bëjë asgjë nëse nuk është njeriu që të analizojë një problem, të formulojë një algoritëm dhe ta kodojë atë në një program.
Kështu ka qenë gjithmonë, derisa filluam të flasim Inteligjenca artificiale. Në fakt, inteligjenca artificiale konsiston në nxitjen e një lloj arsyetimi spontan në makinë, i cili mund ta çojë atë në zgjidhjen e problemeve në mënyrë të pavarur, domethënë pa udhëzim të drejtpërdrejtë njerëzor.
U deshën disa vite para se të shprehej "nxisin një lloj arsyetimi spontan në makinë“, Domethënë, u deshën disa vite para se të kalonim nga një gjendje e udhëzimit total” të detyruar” të makinës, në një gjendje të vetë-mësimit. Me fjalë të tjera, makina ka qenë në gjendje të vetë-mësojë, të mësojë. Prandaj kemi arritur në Mësim Machine.
Mësimi i Makinerisë është një degë e Inteligjencës Artificiale në të cilën programuesi drejton makinën në një fazë trajnimi bazuar në studimin e të dhënave historike. Në përfundim të kësaj faze trajnimi, prodhohet një model që mund të përdoret në zgjidhjen e problemeve, i shpjeguar me të dhëna të reja.
Unë respektoj qasjen klasike, ku dikur punonte shkencëtari i të dhënave defiNish algoritmet e zgjidhjes, makina do të zbulojë se çfarë e përbën modelin. Shkencëtari i të dhënave duhet të kujdeset për organizimin e fazave gjithnjë e më efektive të trajnimit, me të dhëna më të pasura dhe më domethënëse, si dhe për të verifikuar vlefshmërinë e modeleve të prodhuara duke i nënshtruar ato në teste.
Falë Machine Learning, sistemet që përdorim në pajisjet mobile, internet, automatizimin e shtëpisë janë (ose duken) gjithnjë e më inteligjente. Një sistem, siç funksionon, mund të jetë gjithashtu në gjendje të mbledhë të dhëna për të dhe për përdoruesit që e përdorin atë, pastaj t'i përdorë ato në fazën e trajnimit dhe më pas të përmirësojë më tej parashikimet.
Ercole Palmeri: I varur nga inovacioni
Zhvillimi i aftësive të shkëlqyera motorike përmes ngjyrosjes i përgatit fëmijët për aftësi më komplekse si shkrimi. Për të ngjyrosur…
Sektori detar është një fuqi e vërtetë ekonomike globale, e cila ka lundruar drejt një tregu prej 150 miliardë...
Të hënën e kaluar, Financial Times njoftoi një marrëveshje me OpenAI. FT licencon gazetarinë e saj të klasit botëror…
Miliona njerëz paguajnë për shërbimet e transmetimit, duke paguar tarifat mujore të abonimit. Është e zakonshme që ju…

