Në këtë shembull të mësimit të makinerive do të shohim një regresion linear me vetëm një veçori hyrëse. Një regresion i thjeshtë linear.
Përpara se të vazhdoni, ju rekomandoj të lexoni dy artikuj të shkurtër, ku do të gjeni disa definocionet:
Meqenëse do të përdorim Python, nëse nuk e keni ende në kompjuterin tuaj, lexoni më tej Si të instaloni Python në Microsoft Windows
Për shembull, le të shqyrtojmë dy lista Python: e para përfaqëson vlerat hyrëse (tipar), e dyta vlerat e daljes (objektiv).
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
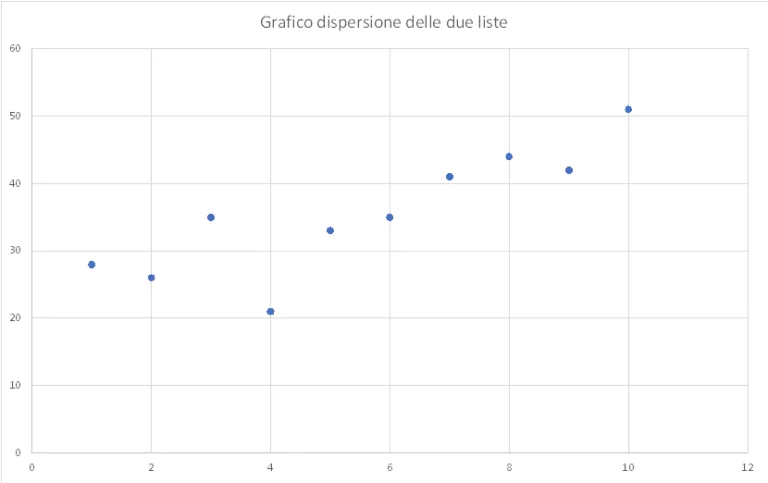
y = [28, 26, 35, 21, 33, 35, 41, 44, 42, 51]
Këto dy lista mund të përfaqësohen në një tabelë me pika shpërndarëse
Nga grafiku mund të shohim se pikat, edhe pse jo në të njëjtën linjë, megjithatë kanë një shpërndarje pothuajse lineare, nga pika e poshtme majtas në pikën e sipërme djathtas. Shpërndarja e pikave në grafik mund të identifikohet si trendi i listave që janë baza e modelit mbi të cilin do të bazohet makina jonë automatike e të mësuarit.
Pra, mund të themi se nëse X rritet, edhe Y rritet, sikur pikat të ishin rreth një vije imagjinare. Qëllimi i regresionit është pikërisht të identifikojë këtë vijë, këtë vijë të drejtë. Identifikimi i kësaj linje do të na ndihmonte për të identifikuar pikat Y për vlerat e X që nuk janë të pranishme në listë.
Në fakt, mund të pyesim veten se si të parashikojmë vlerën e Y për një X që nuk përfshihet në rastet, nuk përfshihet në dy listat? Në thelb, cila do të ishte vlera e Y nëse X do të vlente 11, ose 12, ose 13?
Regresioni linear llogarit vijën që përafron më mirë pikat, pra vijën që kalon midis pikave, duke minimizuar distancën nga secila prej tyre. Dhe duke qenë se regresioni i thjeshtë do të na japë një vijë të drejtë, është e qartë se parashikimi nuk do të jetë aq i saktë, por ne do të jemi ende në gjendje të vlerësojmë një nivel të besueshëm, shumë afër Y.
Le ta bëjmë atë me scikit-learn:
# ne importojmë modelin e regresionit linear nga scikit-learn
importoni numpy si np
nga importi sklearn.linear_model Regresioni Linear
# ne instantojmë modelin
model = Regresion linear ()
# ne inicializojmë vlerat që do të na duhen për të udhëzuar makinën
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y = [28, 26, 35, 21, 33, 35, 41, 44, 42, 51]
# ne i strukturojmë të dhënat në formë dydimensionale
X = np.array (x) .riforma (-1,1)
# ne trajnojmë modelin
model.përshtatje (X, y)
Rezultati i marrë nga kodi Python është a model i arsimuar. Objekti i modelit u instancua nga klasa e regresionit linear dhe pas thirrjes së modelit të përshtatjes, modeli ka studiuar të dhënat dhe është gati të bëjë parashikime.
Për të pasur parashikimin, duhet të përdorim metodën e parashikimit, e cila është përgjegjëse për parashikimin e skenarëve të ardhshëm. Le të shtojmë rreshtin
printim (modeli.parashikoni ([[11], [12], [13], [14]])))
Duke filluar përsëri programin, do të marrim katër vlerat e parashikuara që korrespondojnë me veçoritë 11, 12, 13 dhe 14:
[49.8 52.38181818 54.96363636 57.54545455]
Pra, katër vlerat e marra në korrespondencë janë:
Siç mund ta shohim, rritja e vlerave të X korrespondon me vlerat në rritje të Y, dhe kjo ka kuptim. Le të përpiqemi të shohim se çfarë ndodh në grafik
Vija e kuqe paraqet rezultatin e regresionit. Linja duket të jetë interpretimi gjeometrik, dhe në veçanti linear, i shpërndarjes së pikave. Në thelb është si të thuash se modeli i zgjedhur për të përmirësuar parashikimin është një model i thjeshtë dhe linear.
Mund të themi se parashikimi nuk është shumë i saktë, por është një interpretim.
Pasi të jenë marrë rezultatet e parashikimit, do të jetë e rëndësishme të dini gjithmonë se si të vlerësoni efektivitetin e një modeli. Për ta bërë këtë, ne duhet të shohim matjet që scikit-mësuar vë në dispozicion në paketën sklearn.metrics.
Metrikat bazohen në konceptin e mbetjes, d.m.th. sa larg vija devijon nga vlera e vërtetë e y për një x të caktuar. Praktikisht për çdo pikë distanca nga vija e drejtë e vetë pikës.
Ne mund të llogarisim mbetjet duke llogaritur diferencën midis vlerës reale dhe vlerës së parashikuar, mund ta bëjmë këtë për veçoritë 1 deri në 10:
# llogaritni parashikimet për vlerat x nga 1 në 10
y_pred = model.parashikoj (X)
printim (y_pred)
# llogarit mbetjet
mbetje = y - y_pred
printim (mbetjet)
si rezultat i marr parashikimet
[23.98181818 26.56363636 29.14545455 31.72727273 34.30909091 36.89090909 39.47272727 42.05454545 44.63636364.
dhe mbetjet
[4.01818182 -0.56363636 5.85454545 -10.72727273 -1.30909091 -1.89090909 1.52727273 1.94545455 -2.63636364]
Secila prej këtyre vlerave mat se sa larg ka kaluar vija nga pika në grafik. Quhen pikat me mbetje më të madhe i jashtëm, pra vlerat që janë më pak të përafruara me trendin e përgjithshëm (për shembull tremujori -10.72). Vlera e dytë është -0.56 dhe për këtë arsye shumë në përputhje me trendin e përgjithshëm.
Për regresionin linear ka metrika shumë të rëndësishme që scikit-learn i vë në dispozicion, le të shohim disa prej tyre:
Funksionet e mësimit scikit që përmirësojnë tre treguesit janë:
duke i zbatuar ato në shembullin tonë, marrim vlerat e mëposhtme:
MAE = 3.4254545454545466
MSE = 19.847272727272724
R2 = 0.7348039453865216
nga sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
printim (gabim_mesatar_absolut (y, y_pred))
printim (gabim_mesatar_katror (y, y_pred))
printim (r2_rezultat (y, y_pred))
Ercole Palmeri: I varur nga inovacioni
Një operacion oftalmoplastik duke përdorur shikuesin komercial Apple Vision Pro u krye në Poliklinikën Catania…
Zhvillimi i aftësive të shkëlqyera motorike përmes ngjyrosjes i përgatit fëmijët për aftësi më komplekse si shkrimi. Për të ngjyrosur…
Sektori detar është një fuqi e vërtetë ekonomike globale, e cila ka lundruar drejt një tregu prej 150 miliardë...
Të hënën e kaluar, Financial Times njoftoi një marrëveshje me OpenAI. FT licencon gazetarinë e saj të klasit botëror…


