Di vê mînaka fêrbûna makîneyê de em ê vegerek xêzek bi tenê yek taybetmendiyek têketinê bibînin. Vegerînek xêzikek hêsan.
Berî ku hûn bidomînin, ez ji we re şîret dikim ku hûn du gotarên kurt bixwînin, ku hûn ê çendan bibînin defiramanên:
Ji ber ku em ê Python bikar bînin, heke we hîna li ser PC-ya xwe tune be, bixwînin Meriv çawa Python li ser Microsoft Windows saz dike
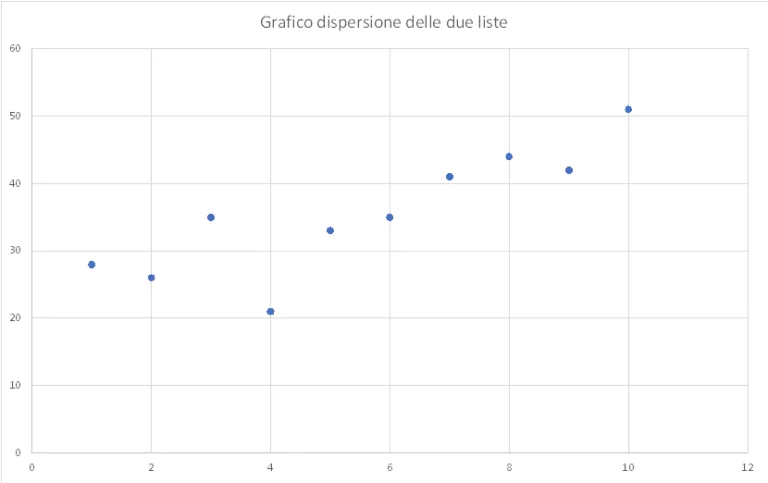
Ji bo nimûne, em du navnîşên Python binirxînin: ya yekem nirxên têketinê nîşan dide (taybetî), ya duyemîn nirxên derketinê (armanc).
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y = [28, 26, 35, 21, 33, 35, 41, 44, 42, 51]
Van her du navnîşan dikarin li ser nexşeyek xala belavkirî bêne temsîl kirin
Ji grafîkê em dikarin bibînin ku xal, her çend ne li ser heman xetê ne, lêbelê xwedan dabeşek hema hema xêzek in, ji xala çepê ya jêrîn berbi xala jorîn rastê. Dabeşkirina xalên li ser grafîkê dikare wekî meyla navnîşên ku bingeha modela ku dê makîneya meya fêrbûna otomatîkî li ser bingeha wê be were nas kirin.
Ji ber vê yekê em dikarin bibêjin ku heke X mezin dibe, heta Y mezin dibe, mîna ku xal li dora xeteke xeyalî bin. Armanca vegerandinê tam naskirina vê xetê, vê xeta rast e. Nasnameya vê xetê dê ji me re bibe alîkar ku em xalên Y ji bo nirxên X yên ku di navnîşê de ne diyar bikin.
Bi rastî, dibe ku em ji xwe bipirsin ka meriv çawa nirxa Y-yê ji bo X-ya ku di nav bûyeran de ne, di nav du navnîşan de ne tê pêşbînîkirin? Di bingeh de heke X nirxa 11, an 12, an 13-ê bûya dê nirxa Y çi be?
Regresîyona xêz xêza ku herî baş nêzî xalan dibe, ango xeta ku di navbera xalan de derbas dibe hesab dike, dûrahiya ji her yekê ji wan kêm dike. Û ji ber ku paşveçûnek hêsan dê xêzek rast bide me, diyar e ku pêşbînkirin dê ne ewqas rast be, lê dîsa jî em ê karibin astek maqûl, pir nêzî Y-ê texmîn bikin.
Ka em wê bi scikit-learn bikin:
# em modela regresyona xêzik ji scikit-learn derdixin
numpy wek np import bike
ji sklearn.linear_model import LinearRegression
# em modelê destnîşan dikin
model = LinearRegression ()
# em nirxên ku em ê hewce bikin ku makîneyê rêwerz bikin dest pê dikin
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y = [28, 26, 35, 21, 33, 35, 41, 44, 42, 51]
# em daneyan bi forma du-alî ava dikin
X = np.array (x) .reshape (-1,1)
# em modelê perwerde dikin
model.fit (X, y)
Encama ku ji koda Python hatî wergirtin a modela perwerdekirî. Tişta modelê ji hêla çîna regresyonê ya xêz ve hate destnîşan kirin, û piştî bangkirina modela guncan, modela daneyan lêkolîn kiriye û amade ye ku pêşbîniyan bike.
Ji bo ku pêşbîniyê hebe divê em rêbaza pêşbîniyê, ku berpirsiyarê pêşbînkirina senaryoyên pêşerojê ye, bişopînin. Ka em rêzê lê zêde bikin
çapkirin (model.pêşbînî ([[11], [12], [13], [14]])))
ji nû ve bernameyê dest pê bikin, em ê çar nirxên pêşbînîkirî yên ku bi taybetmendiyên 11, 12, 13 û 14 re têkildar in bistînin:
[49.8 52.38181818 54.96363636 57.54545455]
Ji ber vê yekê çar nirxên ku di pêwendiyê de têne wergirtin ev in:
Wekî ku em dibînin, zêdekirina nirxên X bi zêdebûna nirxên Y re têkildar e, û ev yek watedar e. Ka em hewl bidin ku bibînin ka li ser grafîkê çi diqewime
Xeta sor encama paşveçûnê nîşan dide. Xêz dixuye ku şiroveya geometrîk û bi taybetî jî xêzkirî ya belavkirina xalan e. Di bingeh de ew e ku meriv bêje ku modela ku ji bo zêdekirina pêşbîniyê hatî hilbijartin modelek hêsan û xêz e.
Em dikarin bibêjin ku pêşbînî ne pir rast e, lê şiroveyek e.
Dema ku encamên pêşbîniyê hatin bidestxistin, ew ê girîng be ku hûn her gav zanibin ka meriv çawa bandora modelek binirxîne. Ji bo vê yekê em hewce ne ku metrîkên ku bibînin scikit-fêr bibin di pakêta sklearn.metrics de peyda dike.
Metrîk li ser bingeha têgeha mayî ye, ango xet çiqas ji nirxa rastîn a y-yê ji bo x-ya diyar dûr dikeve. Bi pratîkî ji bo her nuqteyê dûrbûna ji xeta rast a xalê bixwe.
Em dikarin bermayiyan bi hesabkirina cûdahiya di navbera nirxa rastîn û nirxa pêşbînîkirî de hesab bikin, em dikarin ji bo taybetmendiyên 1 heta 10 bikin:
# pêşbîniyên ji bo x nirxan ji 1 heta 10 hesab bikin
y_pred = model.predict (X)
çapkirin (y_pred)
# bermayiyan hesab bike
bermayî = y - y_pred
çapkirin (bermayî)
di encamê de ez pêşbîniyan distînim
[23.98181818 26.56363636 29.14545455 31.72727273 34.30909091 36.89090909 39.47272727 42.05454545]
û bermayiyan
[4.01818182 -0.56363636 5.85454545 -10.72727273 -1.30909091 -1.89090909 1.52727273 1.94545455 -2.63636364]
Her yek ji van nirxan dipîve ka xêz çiqas ji xala di grafîkê de derbas bûye. Xalên bi bermayiyê mezintir têne gotin outliers, ango, nirxên herî kêm bi meyla gelemperî re hevaheng in (mînak çaryek -10.72). Nirxa duyemîn -0.56 e û ji ber vê yekê pir bi meyla gelemperî re têkildar e.
Ji bo vegerandina xêzik metrîkên pir girîng hene ku scikit-learn peyda dike, em çend ji wan bibînin:
Fonksiyonên fêrbûna scikit-ê ku sê nîşanan zêde dikin ev in:
bi sepandina wan li mînaka me em nirxên jêrîn digirin:
MAE = 3.4254545454545466
MSE = 19.847272727272724
R2 = 0.7348039453865216
ji sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
çapkirin (mean_absolute_error (y, y_pred))
çapkirin (mean_squared_error (y, y_pred))
çapkirin (r2_score (y, y_pred))
Ercole Palmeri: Nûjenî girêdaye
Her operasyona karsaziyê gelek daneyan hildiberîne, tewra di formên cûda de. Vê daneyê bi destan ji pelek Excel têkevin…
Lihevkirina e-nameyên pargîdanî di sê mehên yekem ên 2024-an de li gorî çaryeka paşîn a…
Prensîba veqetandina navberê yek ji pênc prensîbên SOLID yên sêwirana objekt-oriented e. Divê polê hebe…
Microsoft Excel ji bo analîzkirina daneyê amûrek referansê ye, ji ber ku ew ji bo organîzekirina daneyan gelek taybetmendiyan pêşkêşî dike,…
Walliance, SIM û platformê di nav serokên li Ewrûpayê de di warê 2017-an û vir ve Qedexekirina Nekêşbar ragihand…
Filament çarçoveyek pêşkeftina Laravel "lezkirî" ye, ku gelek pêkhateyên tev-stack peyda dike. Ew ji bo hêsankirina pêvajoya…
"Divê ez vegerim da ku pêşveçûna xwe temam bikim: Ez ê xwe di hundurê komputerê de proje bikim û bibim enerjiya paqij. Dema ku li…
Google DeepMind guhertoyek çêtir a modela xweya îstîxbarata sûnî destnîşan dike. Modela nû ya pêşkeftî ne tenê peyda dike…


