U ovom primjeru strojnog učenja vidjet ćemo linearnu regresiju sa samo jednom ulaznom karakteristikom. Jednostavna linearna regresija.
Prije nego što nastavite, preporučujem vam da pročitate dva kratka članka, gdje ćete ih pronaći nekoliko definacije:
Pošto ćemo koristiti Python, ako ga još nemate na svom računaru, čitajte dalje Kako instalirati Python na Microsoft Windows
Za primjer, razmotrimo dvije Python liste: prva predstavlja ulazne vrijednosti (svojstvo), drugi izlazne vrijednosti (cilj).
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y = [28, 26, 35, 21, 33, 35, 41, 44, 42, 51]
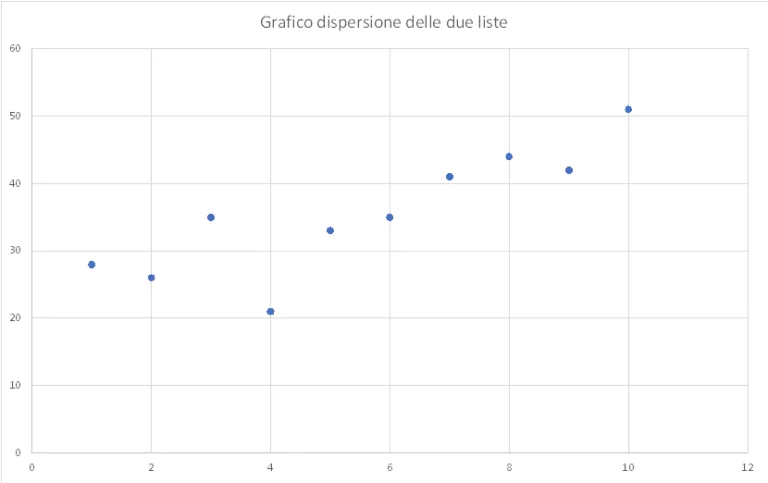
Ove dvije liste mogu biti predstavljene na tačkicama
Iz grafikona možemo vidjeti da tačke, iako nisu na istoj liniji, ipak imaju skoro linearnu distribuciju, od donje lijeve do gornje desne tačke. Raspodjela bodova na grafikonu može se identificirati kao trend lista koje su osnova modela na kojem će se temeljiti naša automatska mašina za učenje.
Tako da možemo reći da ako je X raste, čak i Y raste, kao da su tačke oko zamišljene linije. Cilj regresije je upravo da identifikuje ovu liniju, ovu pravu liniju. Identifikacija ove linije bi nam pomogla da identifikujemo tačke Y za vrednosti X koje nisu prisutne na listi.
U stvari, mogli bismo se zapitati kako predvidjeti vrijednost Y za X koji nije uključen u slučajeve, koji nije uključen u dvije liste? U osnovi, kolika bi bila vrijednost Y da X vrijedi 11, 12 ili 13?
Linearna regresija izračunava liniju koja najbolje aproksimira tačke, odnosno liniju koja prolazi između tačaka, minimizirajući udaljenost od svake od njih. A pošto će nam jednostavna regresija dati ravnu liniju, očigledno je da predviđanje neće biti toliko tačno, ali ćemo i dalje moći da procenimo prihvatljiv nivo, veoma blizu Y.
Uradimo to sa scikit-learn:
# uvozimo model linearne regresije iz scikit-learn-a
uvoz numpy kao np
iz sklearn.linear_model import LinearRegression
# instanciramo model
model = Linearna regresija ()
# inicijaliziramo vrijednosti koje će nam trebati da uputimo mašinu
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y = [28, 26, 35, 21, 33, 35, 41, 44, 42, 51]
# strukturiramo podatke u dvodimenzionalnom obliku
X = np.array (x) .reshape (-1,1)
# obučavamo model
model.fit (X, y)
Rezultat dobiven iz Python koda je a obrazovani model. Objekt modela je instanciran klasom linearne regresije, a nakon pozivanja modela uklapanja, model je proučio podatke i spreman je za predviđanje.
Da bismo imali predviđanje, moramo pozvati metod predviđanja, koji je odgovoran za predviđanje budućih scenarija. Dodajmo red
print (model.predict ([[11], [12], [13], [14]])))
kada ponovo pokrenemo program, dobićemo četiri predviđene vrednosti koje odgovaraju karakteristikama 11, 12, 13 i 14:
[49.8 52.38181818 54.96363636 57.54545455]
Dakle, četiri vrijednosti dobijene u korespondenciji su:
Kao što vidimo, povećanje vrijednosti X odgovara rastućim vrijednostima Y, i to ima smisla. Hajde da pokušamo da vidimo šta se dešava na grafikonu
Crvena linija predstavlja rezultat regresije. Čini se da je linija geometrijska, a posebno linearna, interpretacija raspodjele tačaka. U osnovi, to je kao da kažemo da je model odabran za poboljšanje prognoze jednostavan i linearan model.
Možemo reći da predviđanje nije baš tačno, ali je interpretacija.
Jednom kada se dobiju rezultati predviđanja, bit će važno uvijek znati kako procijeniti efikasnost modela. Da bismo to učinili moramo vidjeti metriku koja scikit-learn čini dostupnim u paketu sklearn.metrics.
Metrika se zasniva na konceptu ostatka, tj. koliko daleko linija odstupa od prave vrijednosti y za dati x. Praktično za svaku tačku udaljenost od prave linije same tačke.
Možemo izračunati ostatke tako što ćemo izračunati razliku između stvarne i predviđene vrijednosti, možemo to učiniti za karakteristike od 1 do 10:
# izračunaj predviđanja za x vrijednosti od 1 do 10
y_pred = model.predict (X)
print (y_pred)
# izračunati ostatke
ostaci = y - y_pred
print (ostaci)
kao rezultat dobijam predviđanja
[23.98181818 26.56363636 29.14545455 31.72727273 34.30909091 36.89090909 39.47272727 42.05454545 44.63636364 47.21818182 XNUMX
i ostaci
[4.01818182 -0.56363636 5.85454545 -10.72727273 -1.30909091 -1.89090909 1.52727273 1.94545455 -2.63636364]
Svaka od ovih vrijednosti mjeri koliko je linija prošla od tačke na grafikonu. Pozivaju se tačke sa većim reziduom outliers, odnosno vrijednosti najmanje usklađene s općim trendom (na primjer kvartal -10.72). Druga vrijednost je -0.56 i stoga je vrlo u skladu sa općim trendom.
Za linearnu regresiju postoje vrlo važne metrike koje scikit-learn čini dostupnim, pogledajmo neke od njih:
Funkcije scikit-learn koje poboljšavaju tri indikatora su:
primjenjujući ih na naš primjer dobijamo sljedeće vrijednosti:
MAE = 3.4254545454545466
MSE = 19.847272727272724
R2 = 0.7348039453865216
iz sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
print (srednja_apsolutna_greška (y, y_pred))
ispis (srednja_kvadratna_greška (y, y_pred))
print (r2_score (y, y_pred))
Ercole Palmeri: Ovisnik o inovacijama
Milioni ljudi plaćaju usluge striminga, plaćajući mjesečne pretplate. Uvriježeno je mišljenje da vi…
Coveware od strane Veeam-a će nastaviti da pruža usluge odgovora na incidente u slučaju sajber iznude. Coveware će ponuditi mogućnosti forenzike i sanacije…
Prediktivno održavanje revolucionira sektor nafte i plina, s inovativnim i proaktivnim pristupom upravljanju postrojenjima.…
UK CMA izdao je upozorenje o ponašanju Big Tech-a na tržištu umjetne inteligencije. Tamo…


