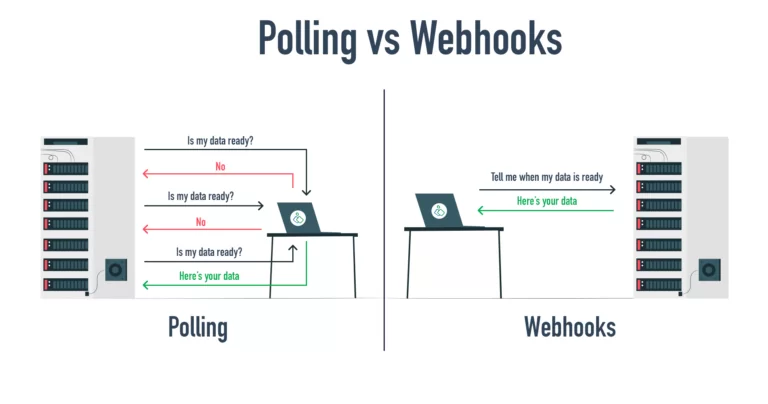
与传统系统(其中一个系统(主体)不断轮询另一个系统(观察者)获取某些数据)不同,Webhook 允许观察者在事件发生时自动将数据推送到主体的系统中。
这消除了对象持续监控的需要。 Webhook 完全在 Internet 上运行,因此系统之间的所有通信都必须以 HTTP 消息的形式进行。
Webhook 依赖于指向主体系统中 API 的静态 URL,当观察者系统中发生事件时需要通知这些 API。 一个例子是一个网络应用程序,旨在收集和管理用户亚马逊帐户上的所有订单。 在此场景中,Amazon 充当观察者,Custom Order Management Webapp 充当主体。
自定义 Web 应用程序中创建的 Webhook 将允许亚马逊通过注册的 URL 自动提交在 Web 应用程序中新创建的订单,而不是让自定义 Web 应用程序定期调用 Amazon API 来检查创建的订单。 因此,要启用 Webhooks,主体必须具有指定的 URL 来接受来自观察者的事件通知。 这减少了对象上的显着负载,因为仅当事件发生时才在两方之间进行 HTTP 调用。
一旦观察者调用主体的 Webhook,主体就可以对新提交的数据采取适当的操作。 通常,Webhook 是通过对特定 URL 发出 POST 请求来完成的。 POST 请求允许您向对象发送附加信息。 此外,它还可以用于识别多种可能的事件,而不是为每个事件创建单独的 Webhook URL。
要在您的应用程序上实施入站 Webhook,您需要执行以下基本步骤:
Webhooks 和 API 的目标都是在应用程序之间建立通信。 然而,使用 Webhooks 相对于 API 来实现应用程序集成有一些明显的优点和缺点。
如果以下几点与已实现的系统更相关,那么 Webhooks 往往是更好的解决方案:
在某些其他情况下,使用 API 应该优于 Webhook。
在 Webhooks 上使用 API 需要考虑的重要事项是:
为了应对 Webhook 脱机时丢失从服务器发送的数据的可能性,您可以使用事件消息队列来存档这些调用。 提供此类功能的平台示例包括 的RabbitMQ o Amazon 的简单队列服务 (SQS)。 两者都被设计为充当中间消息存储设施,以避免错过 Webhook 调用的可能性。
Ercole Palmeri

