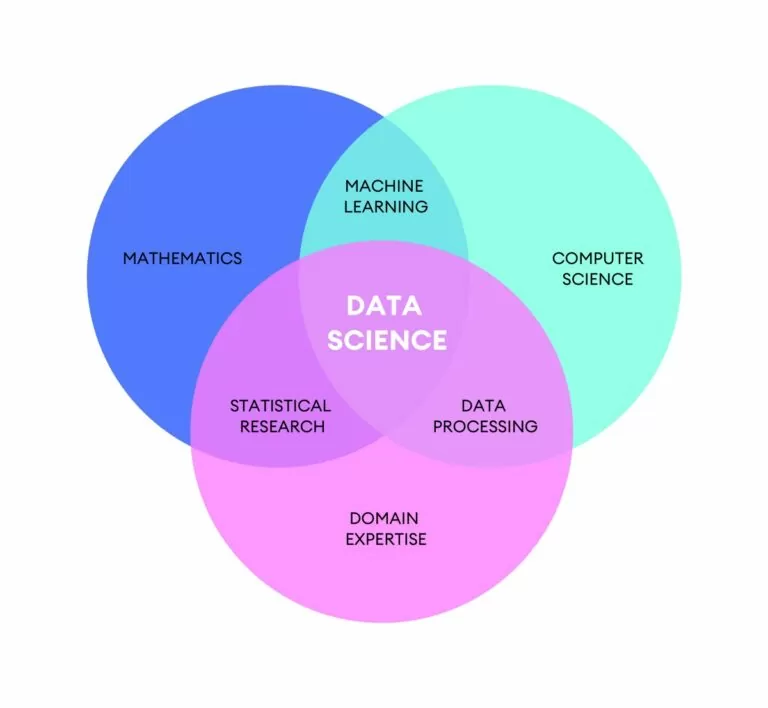
La Data Science, లేదా డేటా సైన్స్, సాపేక్షంగా కొత్త సైన్స్, వాస్తవానికి ఇది సుమారు యాభై సంవత్సరాలుగా ఉంది. ఇది చాలా సజీవంగా మరియు వేగంగా అభివృద్ధి చెందుతున్న సందర్భంలో క్రమంలో ఉంచవలసిన అవసరం నుండి పుడుతుంది. డేటా పరిమాణంలో పెరుగుదల, డేటాకు అర్థం చెప్పే అవకాశం మరియు సామర్థ్యం Data Science.
చారిత్రాత్మకంగా చెప్పాలంటే, డేటా తరచుగా ఏదైనా ప్రక్రియ యొక్క ద్వితీయ ఉత్పత్తిగా పరిగణించబడుతుంది. శతాబ్దాలుగా ఎవరైనా డేటాను సేకరించే పనిలో ఉన్నారు, ప్రధానంగా వారి స్వంత సౌలభ్యం కోసం అలా చేసారు, తరచుగా ఊహించకుండానే నేడు డేటా సేకరణకు ఆర్థిక విలువను ఆపాదించవచ్చు. ఉదాహరణకు, పంటలు, సంఘటనలు, విత్తనాలు మొదలైన వాటిపై సంవత్సరాల తరబడి సమాచారాన్ని సేకరించిన పొలం గురించి మనం అనుకుంటే, బహుశా అది దాని కార్పొరేట్ చరిత్రను ఆర్కైవ్ చేయడానికి అలా చేసి ఉండవచ్చు. అన్ని పొలాలు ఆ పద్ధతిని చేసి ఉంటే, ఈ రోజు ఎరువుల కంపెనీలు పరిశోధన ప్రయోజనాల కోసం లేదా మార్కెటింగ్ ప్రయోజనాల కోసం దాని నుండి ప్రయోజనం పొందుతాయి.
వ్యవహరించే వాడు Data Science, అతను అంటారు డేటా సైంటిస్ట్: ప్రస్తుతం పని ప్రపంచంలో అత్యంత కోరిన నిపుణులలో ఒకరు.
డేటా సైంటిస్ట్ యొక్క పని ఏమిటంటే, వాటిలోని నమూనాలను గుర్తించడానికి డేటాను విశ్లేషించడం, అంటే నేను ట్రెండ్ ద్వారా అందుబాటులో ఉన్న డేటాను వ్యక్తపరుస్తాను. ఈ నమూనాల గుర్తింపు క్లయింట్ యొక్క ప్రయోజనాలకు అనుగుణంగా ఉంటుంది: కంపెనీ, పబ్లిక్ బాడీ మొదలైనవి ...
ఇటీవలి సంవత్సరాలలో, డేటా మార్కెటింగ్ మోడల్ ఎక్కువగా స్థిరపడింది, ఇక్కడ ఎవరైనా డేటాను విక్రయించడానికి మరియు మరొకరు దానిని కొనుగోలు చేయడానికి ఆసక్తి చూపుతున్నారు.
డేటా ఉత్పత్తిలో నైపుణ్యం కలిగిన కంపెనీలు పుట్టుకొచ్చాయి మరియు తగిన క్లీనింగ్ మరియు రీప్రాసెసింగ్ కార్యకలాపాల తర్వాత కొనుగోలు చేయడం మరియు విక్రయించడంలో కంపెనీలు ప్రత్యేకత కలిగి ఉన్నాయి. మనం గోప్యతా నిబంధనల గురించి ఆలోచిస్తే, విషయం యొక్క సంక్లిష్టత మనకు తెలుస్తుంది. నేడు సమాచారాన్ని స్పృహతో మరియు గౌరవప్రదంగా ఉపయోగించాలని పిలుపునిచ్చే కఠినమైన చట్టాలు ఉన్నాయి.
యొక్క ఒక ప్రాజెక్ట్ Data Science సాధారణంగా క్రింది దశలను కలిగి ఉంటుంది:
ప్రతి ఒక్క అడుగులో ది డేటా సైంటిస్ట్ నిర్దిష్ట కంపెనీ విభాగాలతో సంకర్షణ చెందుతుంది, కాబట్టి మేము చెప్పగలం డేటా సైంటిస్ట్ కార్పొరేట్ రియాలిటీలో సంపూర్ణంగా విలీనం చేయబడింది.
సాంకేతిక అభివృద్ధితో, ది డేటా సైంటిస్ట్ అతను తరచుగా బిగ్ డేటా మరియు ఆర్టిఫిషియల్ ఇంటెలిజెన్స్ సమస్యలను ఎదుర్కొంటున్నాడు.
మేము బిగ్ డేటా గురించి మాట్లాడేటప్పుడు, వాల్యూమ్లు పెరుగుతూ మరియు ఎక్కువ వేగంతో వచ్చే అనేక రకాల డేటాను సూచిస్తాము. ఈ భావనను మూడు Vs యొక్క నియమం అని కూడా పిలుస్తారు, ఇది బిగ్ డేటా దృగ్విషయాన్ని దాని ముఖ్యమైన లక్షణాలలో వర్ణించే మూడు పదాల ఎంపికలో ఉంటుంది:
వాస్తవానికి, డేటా యొక్క విశ్వసనీయత మరియు విశ్వసనీయతను గుర్తించడానికి డేటా యొక్క నిజాయితీ వంటి ఇతర ప్రత్యేకతలు కూడా కాలక్రమేణా జోడించబడ్డాయి.
అధిక వేగంతో వచ్చే డేటా యొక్క పెద్ద పరిమాణం మరియు అనేక రకాలుగా వర్ణించబడి, తప్పనిసరిగా డేటా సంస్థ సమస్యలకు దారి తీస్తుంది.
వాటిని స్వాగతించి, ఆపై వాటిని ప్రాసెస్ చేస్తున్నారా? వాటిని స్ట్రక్చర్ చేసి, ఆపై ప్రాసెస్ చేస్తున్నారా?
డేటా సిస్టమ్స్ యొక్క సంస్థ యొక్క అనేక నమూనాలు పుట్టుకొచ్చాయి, ఇవి కాలక్రమేణా తమను తాము స్థాపించుకున్నాయి:
ప్రస్తుతం ఇవి అత్యంత విస్తృతంగా ఉపయోగించే నమూనాలు, మరియు అనేక సందర్భాల్లో ఏకీకరణ యొక్క పరిష్కారం ప్రబలంగా ఉంది, అనగా వివిధ ప్రాజెక్ట్లు విభిన్న సంచిత పద్ధతులను ఉపయోగించుకోవచ్చు మరియు తరువాత సమయంలో ఏకీకృతం చేయవచ్చు. విభిన్న నమూనాలతో విభిన్న డేటా సేకరించబడే పరిస్థితులు ఉండవచ్చు లేదా విభిన్న సేకరణలు ఒకే జీవిత చక్రం యొక్క పరస్పర దశలను ఏర్పరుస్తాయి.
వాటి గొప్ప ఉపయోగం ఉన్నప్పటికీ, ప్రాసెసింగ్ మెషీన్లు లేదా కంప్యూటర్లు తెలివితక్కువవని మాకు బాగా తెలుసు. అంటే, ఒక సమస్యను విశ్లేషించడం, ఒక అల్గారిథమ్ను రూపొందించడం మరియు ప్రోగ్రామ్లో ఎన్కోడ్ చేయడం మానవుడు కాకపోతే కంప్యూటర్ ఏమీ చేయదు.
మేము మాట్లాడటం ప్రారంభించే వరకు ఇది ఎల్లప్పుడూ కేసు కృత్రిమ మేధస్సు. వాస్తవానికి, కృత్రిమ మేధస్సు అనేది యంత్రంలో ఒక రకమైన ఆకస్మిక తార్కికతను ప్రేరేపించడంలో ఉంటుంది, ఇది స్వతంత్రంగా సమస్యలను పరిష్కరించడానికి దారి తీస్తుంది, అంటే ప్రత్యక్ష మానవ మార్గదర్శకత్వం లేకుండా.
వ్యక్తీకరణకు చాలా సంవత్సరాలు పట్టింది"యంత్రంలో ఒక రకమైన ఆకస్మిక తార్కికతను ప్రేరేపిస్తుంది“, అంటే, మేము యంత్రం యొక్క మొత్తం“ బలవంతపు ” సూచనల నుండి స్వీయ-అభ్యాస స్థితికి వెళ్ళడానికి చాలా సంవత్సరాలు పట్టింది. మరో మాటలో చెప్పాలంటే, యంత్రం స్వీయ-నేర్చుకోగలిగింది, నేర్చుకోవడం. అందువల్ల మేము చేరుకున్నాము యంత్ర అభ్యాస.
మెషిన్ లెర్నింగ్ అనేది ఆర్టిఫిషియల్ ఇంటెలిజెన్స్ యొక్క ఒక శాఖ, దీనిలో ప్రోగ్రామర్ చారిత్రక డేటా అధ్యయనం ఆధారంగా శిక్షణ దశలో యంత్రాన్ని నడుపుతాడు. ఈ శిక్షణ దశ ముగింపులో, కొత్త డేటాతో వివరించిన సమస్యలను పరిష్కరించడంలో వర్తించే మోడల్ ఉత్పత్తి చేయబడుతుంది.
డేటా సైంటిస్ట్ పని చేసే క్లాసిక్ విధానాన్ని నేను గౌరవిస్తాను defiనిష్ సొల్యూషన్ అల్గారిథమ్లు, మెషిన్ మోడల్ను రూపొందించే వాటిని కనుగొంటుంది. డేటా సైంటిస్ట్ ధనిక మరియు మరింత ముఖ్యమైన డేటాతో మరింత ప్రభావవంతమైన శిక్షణా దశలను నిర్వహించడం మరియు పరీక్షలకు లోబడి ఉత్పత్తి చేయబడిన నమూనాల చెల్లుబాటును ధృవీకరించడం వంటి వాటిపై శ్రద్ధ వహించాలి.
మెషిన్ లెర్నింగ్కు ధన్యవాదాలు, మొబైల్ పరికరాలు, ఇంటర్నెట్, హోమ్ ఆటోమేషన్లో మనం ఉపయోగించే సిస్టమ్లు మరింత తెలివైనవి (లేదా అనిపించేలా) ఉన్నాయి. ఒక సిస్టమ్, అది పని చేస్తున్నప్పుడు, దానిపై మరియు దానిని ఉపయోగించే వినియోగదారులపై డేటాను కూడా సేకరించగలదు, ఆపై శిక్షణ దశలో వాటిని ఉపయోగించుకుని, ఆపై అంచనాలను మరింత మెరుగుపరుస్తుంది.
Ercole Palmeri: ఆవిష్కరణకు బానిస
ఆపిల్ విజన్ ప్రో కమర్షియల్ వ్యూయర్ని ఉపయోగించి ఆప్తాల్మోప్లాస్టీ ఆపరేషన్ కాటానియా పాలిక్లినిక్లో నిర్వహించబడింది…
కలరింగ్ ద్వారా చక్కటి మోటారు నైపుణ్యాలను పెంపొందించుకోవడం, రాయడం వంటి క్లిష్టమైన నైపుణ్యాల కోసం పిల్లలను సిద్ధం చేస్తుంది. రంగు వేయడానికి…
నావికా రంగం నిజమైన ప్రపంచ ఆర్థిక శక్తి, ఇది 150 బిలియన్ల మార్కెట్ వైపు నావిగేట్ చేసింది...
గత సోమవారం, ఫైనాన్షియల్ టైమ్స్ OpenAIతో ఒప్పందాన్ని ప్రకటించింది. FT దాని ప్రపంచ స్థాయి జర్నలిజానికి లైసెన్స్ ఇస్తుంది…

