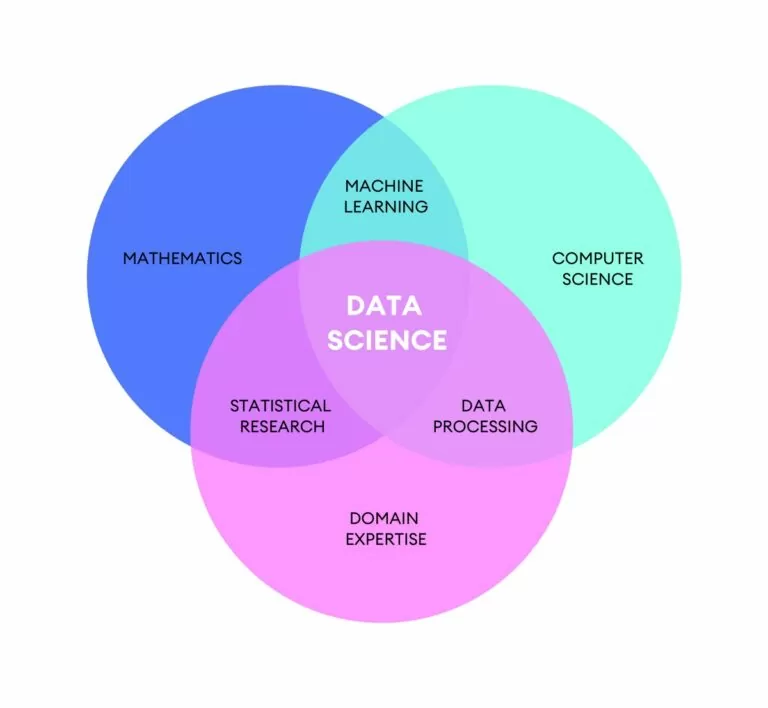
La Data Science, वा डेटा विज्ञान, एक अपेक्षाकृत नयाँ विज्ञान हो, वास्तवमा यो लगभग पचास वर्ष को लागी भएको छ। यो धेरै जीवन्त र द्रुत रूपमा विकसित सन्दर्भमा अर्डर राख्नु पर्ने आवश्यकताबाट उत्पन्न हुन्छ। डाटाको मात्रामा भएको बृद्धि, तथ्याङ्कलाई अर्थ दिने सम्भावना र क्षमताले तथ्याङ्कलाई बढाएको छ Data Science.
ऐतिहासिक रूपमा बोल्दा, डेटालाई प्रायः कुनै पनि प्रक्रियाको माध्यमिक उत्पादनको रूपमा व्यवहार गरिएको छ। शताब्दीयौंदेखि जो कोहीले पनि डाटा सङ्कलन गर्न थालेको छ, मुख्यतया आफ्नो सुविधाको लागि यो गरेको छ, प्रायः कल्पना नगरी। आज एक आर्थिक मूल्य डेटा को एक संग्रह को श्रेय दिन सकिन्छ। यदि हामीले सोच्यौं भने, उदाहरणका लागि, वर्षौंदेखि बाली, घटनाहरू, रोपाइँ, इत्यादिका बारेमा जानकारी सङ्कलन गरेको फार्मको बारेमा, सायद यसले यसको कर्पोरेट इतिहास अभिलेख गर्न त्यसो गरेको हुन सक्छ। यदि सबै फार्महरूले त्यो विधि गरेको भए, आज मल कम्पनीहरूले अनुसन्धान उद्देश्यका लागि वा मार्केटिंग उद्देश्यका लागि यसको फाइदा लिन सक्थे।
जसले व्यवहार गर्छ Data Science, उसलाई बोलाइएको छ डाटा वैज्ञानिक: हाल कामको संसारमा सबैभन्दा धेरै खोजिने पेशेवरहरू मध्ये एक।
डाटा वैज्ञानिकको कार्य भनेको तिनीहरू भित्रका मोडेलहरू पहिचान गर्न डाटाको विश्लेषण गर्नु हो, त्यो हो, जुन म प्रवृत्ति मार्फत उपलब्ध डाटा व्यक्त गर्दछु। यी मोडेलहरूको पहिचान ग्राहकको उद्देश्यका लागि कार्यात्मक छ: कम्पनी, सार्वजनिक निकाय आदि ...
हालैका वर्षहरूमा, डेटा मार्केटिङ मोडेल बढ्दो रूपमा स्थापित भएको छ जहाँ कोही डाटा बेच्न र अरू कसैले यसलाई किन्नमा रुचि राख्छन्।
डाटा उत्पादनमा विशेष कम्पनीहरू जन्मिएका थिए, र कम्पनीहरू उपयुक्त सफाई र पुन: प्रशोधन कार्यहरू पछि खरिद र बिक्रीमा विशेषज्ञ थिए। यदि हामीले गोपनीयता नियमहरूको बारेमा सोच्यौं भने, हामीले विषयको जटिलता महसुस गर्छौं। आज त्यहाँ कडा कानूनहरू छन् जसले जानकारीको सचेत र सम्मानजनक प्रयोगको लागि कल गर्दछ।
को एक परियोजना Data Science सामान्यतया निम्न चरणहरू समावेश छन्:
प्रत्येक एक कदम मा डाटा वैज्ञानिक विशिष्ट कम्पनी विभागहरु संग अन्तरक्रिया गर्दछ, र त्यसैले हामी भन्न सक्छौं कि डाटा वैज्ञानिक कर्पोरेट वास्तविकतामा पूर्ण रूपमा एकीकृत छ।
प्राविधिक विकास संग, द डाटा वैज्ञानिक उनी प्रायः बिग डाटा र आर्टिफिसियल इन्टेलिजेन्सको समस्याको सामना गरिरहेका छन्।
जब हामी बिग डाटाको बारेमा कुरा गर्छौं हामी डेटालाई सन्दर्भ गर्छौं जुन ठूलो विविधता समावेश गर्दछ, बढ्दो भोल्युममा र ठूलो गतिमा आइपुग्छ। यस अवधारणालाई तीन Vs को नियमको रूपमा पनि चिनिन्छ, जुन तीनवटा सर्तहरूको छनोटमा समावेश हुन्छ जसले बिग डाटा घटनालाई यसको आवश्यक विशेषताहरूमा चित्रण गर्दछ:
वास्तविकतामा, समयसँगै अन्य विशेषताहरू पनि थपिएका छन्, जस्तै डाटाको विश्वसनीयता र विश्वसनीयता पहिचान गर्न डाटाको सत्यता।
डाटाको ठूलो मात्रा ठूलो गतिमा आइपुग्छ, र ठूलो विविधताद्वारा विशेषता, आवश्यक रूपमा डाटा संगठन समस्याहरू निम्त्याउँछ।
तिनीहरूलाई स्वागत र त्यसपछि तिनीहरूलाई प्रशोधन? तिनीहरूलाई संरचना र त्यसपछि तिनीहरूलाई प्रशोधन?
डाटा प्रणालीहरूको संगठनका धेरै प्रतिमानहरू जन्मिएका थिए, जसले समयसँगै आफूलाई स्थापित गरेको छ:
हाल यी सबै भन्दा व्यापक रूपमा प्रयोग गरिएका प्रतिमानहरू हुन्, र धेरै अवस्थामा एकीकरणको समाधान प्रबल हुन्छ, अर्थात् विभिन्न परियोजनाहरूले विभिन्न संचयन विधिहरू प्रयोग गर्न सक्छन् र त्यसपछि आफूलाई एकीकरण गर्न सक्छन्। त्यहाँ परिस्थितिहरू हुन सक्छ जसमा विभिन्न डेटाहरू विभिन्न प्रतिमानहरूसँग सङ्कलन गरिन्छ, वा विभिन्न सङ्कलनहरूले एउटै जीवन चक्रको सन्निहित चरणहरू गठन गर्न सक्छन्।
तिनीहरूको ठूलो उपयोगिताको बावजुद, हामीलाई राम्रोसँग थाहा छ कि प्रशोधन मेसिन वा कम्प्युटरहरू मूर्ख छन्। अर्थात्, कम्प्युटरले कुनै समस्याको विश्लेषण गर्ने, एल्गोरिदम तयार गर्ने र प्रोग्राममा सङ्केत गर्ने मान्छे नभएको खण्डमा केही गर्न सक्दैन।
यो सधैं मामला भएको छ, जब सम्म हामीले कुरा गर्न थाले कृत्रिम खुफिया। वास्तवमा, आर्टिफिसियल इन्टेलिजेन्सले मेसिनमा एक प्रकारको सहज तर्कलाई उत्प्रेरित गर्न समावेश गर्दछ, जसले यसलाई स्वतन्त्र रूपमा समस्याहरू समाधान गर्न नेतृत्व गर्न सक्छ, अर्थात् प्रत्यक्ष मानव मार्गदर्शन बिना।
यो अभिव्यक्ति अघि धेरै वर्ष लाग्यो "मेसिनमा एक प्रकारको सहज तर्क उत्पन्न गर्नुहोस्", अर्थात्, हामीले मेसिनको पूर्ण" जबरजस्ती" निर्देशनको अवस्थाबाट, आत्म-शिक्षाको सर्तमा पार गर्न धेरै वर्ष लाग्यो। अर्को शब्दमा भन्नुपर्दा, मेसिनले आत्म-सिक्न, सिक्न सक्षम भएको छ। त्यसैले हामी आइपुगेका छौं मिसिन प्रशिक्षण.
मेसिन लर्निङ आर्टिफिसियल इन्टेलिजेन्सको एउटा शाखा हो जसमा प्रोग्रामरले ऐतिहासिक तथ्याङ्कको अध्ययनमा आधारित प्रशिक्षण चरणमा मेसिन चलाउँछ। यस प्रशिक्षण चरणको अन्त्यमा, एउटा मोडेल उत्पादन गरिन्छ जुन समस्याहरू समाधान गर्न लागू गर्न सकिन्छ, नयाँ डेटाको साथ व्याख्या गरिएको छ।
म क्लासिक दृष्टिकोणको सम्मान गर्छु, जहाँ डेटा वैज्ञानिकले काम गर्थे definish समाधान एल्गोरिदम, मेसिनले मोडेल के बनाउँछ पत्ता लगाउनेछ। डाटा वैज्ञानिकले बढ्दो प्रभावकारी प्रशिक्षण चरणहरू व्यवस्थित गर्न, धनी र अधिक महत्त्वपूर्ण डेटाको साथ, र तिनीहरूलाई परीक्षणको अधीनमा राखेर उत्पादित मोडेलहरूको वैधता प्रमाणित गर्ने कुरामा ध्यान दिनुपर्दछ।
मेसिन लर्निङका लागि धन्यवाद, हामीले मोबाइल उपकरण, इन्टरनेट, गृह स्वचालनमा प्रयोग गर्ने प्रणालीहरू (वा देखिन्छ) अधिक र अधिक बुद्धिमान छन्। प्रणाली, जसरी यसले काम गर्दछ, त्यसमा र यसलाई प्रयोग गर्ने प्रयोगकर्ताहरूमा डेटा सङ्कलन गर्न, त्यसपछि तिनीहरूलाई प्रशिक्षण चरणमा प्रयोग गर्न र त्यसपछि पूर्वानुमानहरू सुधार गर्न सक्षम हुन सक्छ।
Ercole Palmeri: नवप्रवर्तन लत
माइक्रोसफ्ट एक्सेल डाटा विश्लेषणको लागि सन्दर्भ उपकरण हो, किनकि यसले डाटा सेटहरू व्यवस्थित गर्नका लागि धेरै सुविधाहरू प्रदान गर्दछ,…
रियल इस्टेट क्राउडफन्डिङको क्षेत्रमा 2017 देखि युरोपका नेताहरू बीच Walliance, SIM र प्लेटफर्म, पूरा भएको घोषणा गर्दछ ...
फिलामेन्ट एक "त्वरित" Laravel विकास फ्रेमवर्क हो, धेरै पूर्ण-स्ट्याक घटकहरू प्रदान गर्दछ। यो प्रक्रियालाई सरल बनाउन डिजाइन गरिएको हो ...
"मैले मेरो विकास पूरा गर्न फर्कनु पर्छ: म आफैलाई कम्प्युटर भित्र प्रस्तुत गर्नेछु र शुद्ध ऊर्जा बन्नेछु। एक पटक बसोबास गरेपछि…
Google DeepMind ले आफ्नो आर्टिफिसियल इन्टेलिजेन्स मोडेलको सुधारिएको संस्करण प्रस्तुत गर्दैछ। नयाँ सुधारिएको मोडेलले न केवल…
Laravel, यसको सुरुचिपूर्ण सिन्ट्याक्स र शक्तिशाली सुविधाहरूको लागि प्रसिद्ध, पनि मोड्युलर वास्तुकलाको लागि ठोस आधार प्रदान गर्दछ। त्यहाँ…
Cisco र Splunk ले ग्राहकहरूलाई भविष्यको सुरक्षा अपरेसन सेन्टर (SOC) मा आफ्नो यात्रा तिब्र बनाउन मद्दत गर्दैछ...
Ransomware पछिल्लो दुई वर्ष देखि समाचार हावी छ। धेरैजसो मानिसहरूलाई राम्रोसँग थाहा छ कि आक्रमणहरू ...

